
In the architecture of modern software—a sprawling ecosystem of microservices, cloud dependencies, and distributed databases—failure is not a question of “if” but “when.” Networks partition, third-party APIs throttle, data centers experience outages, and new code deployments introduce unexpected side effects. Traditional reliability testing, which often assumes a controlled, predictable environment, is inadequate for this reality. It verifies that systems work under ideal conditions but tells us little about how they will behave when the inevitable chaos of production strikes.
This is where chaos testing, also known as chaos engineering, transcends traditional quality assurance. It is not a testing technique in the conventional sense of validation; it is a proactive discipline of empirical inquiry. Its core philosophy is revolutionary yet simple: to build confidence in a system’s resilience, you must deliberately, yet safely, inject failure into it during normal operation. By observing how the system responds, you can uncover hidden weaknesses, validate assumptions, and engineer true fault tolerance before customers are impacted.
This guide delves into the principles, practices, and profound benefits of making chaos testing an integral part of your journey toward building truly resilient systems.
The Core Philosophy: From Fear of Failure to Learning from It
Chaos testing flips the traditional risk-averse mindset on its head. Instead of hoping failures don’t happen, it assumes they will and seeks them out in a controlled manner. The goal is not to cause outages but to prevent them.
-
The Shift to Proactive Resilience: Traditional approaches are reactive—you find a bug and fix it. Chaos engineering is proactive—you hypothesize about a potential failure mode (e.g., “If our primary database loses latency, the cache should prevent a user-facing timeout”), design an experiment to test that hypothesis, and learn from the outcome. This transforms resilience from a hopeful feature into a verifiable property of the system.
-
Building the “Muscle Memory” for Failure: By regularly experiencing small, controlled failures, your system and, crucially, your team develop “muscle memory.” Engineers learn how the system truly degrades, automation scripts are triggered to remediate issues, and on-call procedures are refined. This ensures that when a real, unexpected failure occurs, the response is calm, practiced, and effective.
The Chaos Testing Cycle: A Methodical Approach to Mayhem
Contrary to its name, chaos testing is highly structured. It follows a continuous, scientific cycle to ensure learning is maximized and risk is minimized.
1. Formulate a Steady-State Hypothesis
This is the foundational step. You must define a measurable, quantitative “steady state” that represents normal, healthy system behavior. This isn’t just “the system is up”; it’s a business-oriented metric like:
“The 95th percentile of user checkout requests completes in under 2 seconds,” or “The error rate for API /user/profile is below 0.1%.”
The hypothesis is a prediction: “We believe that our system will maintain this steady state even during the following disruption…”
2. Design and Scope a Chaos Experiment
Next, you design the simulated failure, or “chaos blast.” This must be a real-world potential event. Examples include:
-
Resource Exhaustion: Inject CPU spike, memory leak, or disk I/O latency on a critical service.
-
Network Issues: Simulate network latency, packet loss, or completely block traffic between two microservices (simulating a network partition).
-
Dependency Failure: Shut down or throttle a third-party API or an internal dependency like a payment service.
-
State Corruption: Introduce corrupted messages into a message queue or faulty data into a cache.
Critically, the experiment must be scoped (e.g., only affect 5% of user traffic) and have a clear, automated abort switch (a “kill switch”) to stop the experiment if impact becomes severe.
3. Execute the Experiment in Production
This is the most counterintuitive yet vital principle: run experiments in production. Staging or pre-production environments are imperfect replicas; they have different traffic patterns, data shapes, and hardware. To have genuine confidence, you must test where your real users are. This is why the principles of scope, monitoring, and abort switches are non-negotiable.
4. Observe and Analyze the Results
During and after the experiment, you rigorously monitor your system. Did the steady-state metrics hold? Did the system degrade gracefully, or did it fail catastrophically? You’re looking for:
-
Verification: The hypothesis was correct, and resilience worked as designed (e.g., traffic successfully failed over to a secondary region).
-
Discovery: A hidden, unexpected vulnerability was revealed (e.g., a downstream service you didn’t know about started timing out, causing a cascade).
-
Learning: Even if the system remained stable, you may discover that your monitoring was inadequate to detect the issue or that alerting thresholds need adjustment.
5. Learn, Improve, and Repeat
The cycle concludes with action. Document every finding. If a weakness is found, fix it—whether it’s adding a circuit breaker, improving retry logic, or creating a new monitoring dashboard. Then, formulate a new hypothesis and begin again. Chaos testing becomes a continuous practice, not a one-off project.
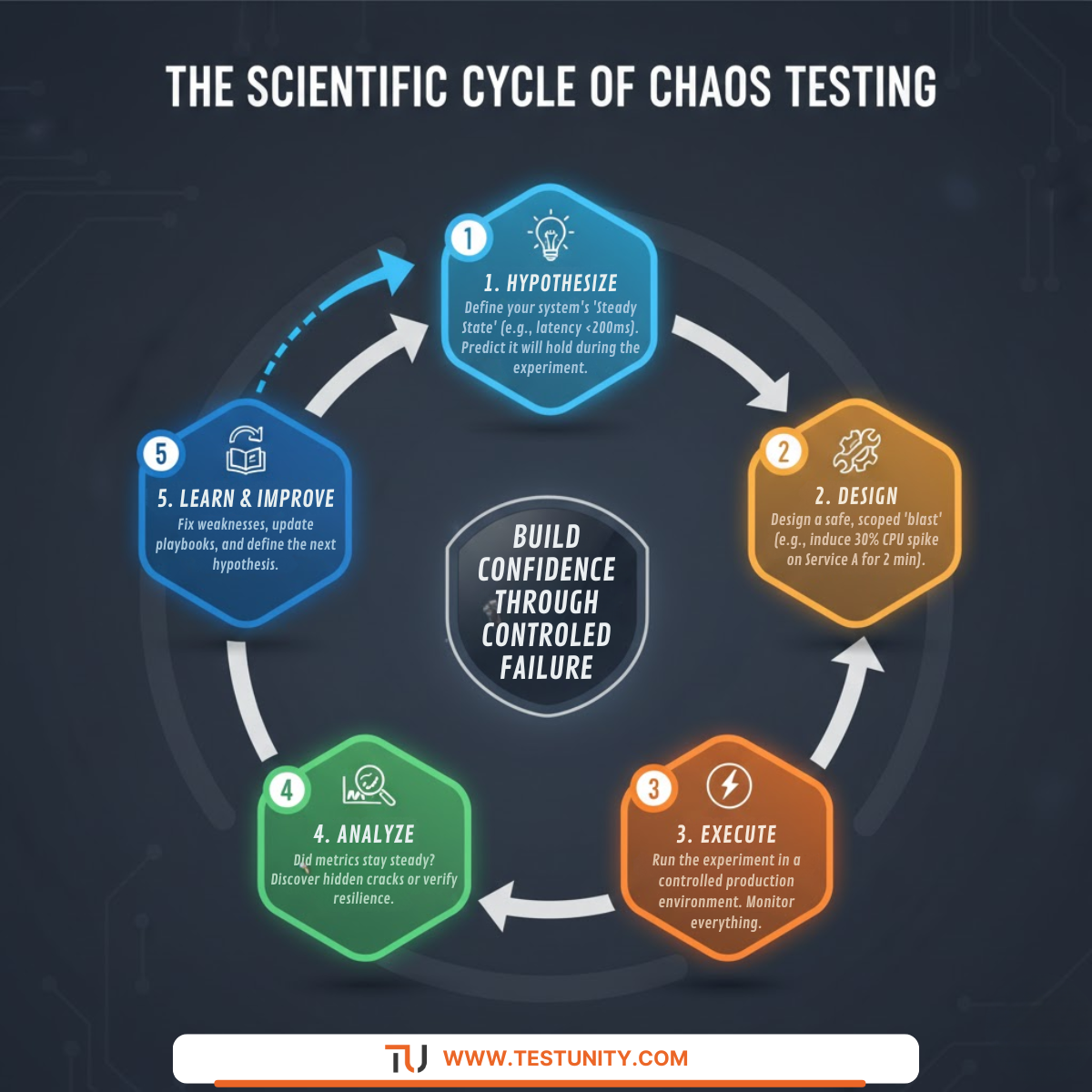
Master the method behind the mayhem. True chaos engineering isn’t random; it’s a rigorous, scientific cycle for continuously strengthening your systems against real-world failure.
Core Principles: The Rules of Engagement
To practice chaos testing responsibly, several core principles must be ingrained:
-
Minimize Blast Radius: Always start small. Target a single, non-critical service or a tiny percentage of traffic. As confidence grows, the scope can slowly increase.
-
Have a Plan to Abort: Before flipping the switch, everyone must know how to stop the experiment instantly. This is typically an automated rollback based on key health metrics.
-
Hypothesis-Driven, Not Random: Chaos is not about randomly killing servers for fun (“monkey testing”). Every experiment must test a specific hypothesis about system behavior.
-
Involve and Communicate: The entire engineering and product organization should be aware of the chaos testing program. Surprising your on-call engineer with a simulated database failure is a recipe for disaster and eroded trust.
Chaos Testing vs. Traditional Testing: A Critical Comparison
It’s essential to understand where chaos testing fits within your broader quality strategy. It does not replace other methods but complements them uniquely.
| Aspect | Traditional Testing (e.g., Unit, Integration, Performance) | Chaos Testing (Chaos Engineering) |
|---|---|---|
| Primary Goal | Validation. Verify the system behaves correctly under defined, expected conditions. | Exploration. Discover how the system behaves under undefined, unexpected failure conditions. |
| Mindset | “Does the system work as we designed it?” | “How does the system fail, and can it withstand surprises?” |
| Environment | Ideally executed in pre-production/staging environments. | Must be executed in production (with controls) to be meaningful. |
| Focus | Functionality, correctness, performance under load. | Resilience, fault tolerance, redundancy, and human response procedures. |
| Nature | Deterministic and scripted. The same test should always produce the same result. | Empirical and experimental. Each test is a learning opportunity that may yield different insights. |

Don’t choose one—integrate both. Traditional testing ensures your system is built right. Chaos testing ensures it’s built to survive the unpredictable real world.
Common Misconceptions and Challenges
-
“It’s Just Breaking Things in Prod”: This is the most common misunderstanding. Without the rigorous, hypothesis-driven framework and safety controls, randomly causing failures is recklessness, not engineering.
-
“We’re Not Netflix; We Don’t Need This”: While pioneered by web-scale companies, the principles apply to any system where availability matters. The complexity of modern cloud-native applications, even in mid-sized companies, creates ample need for resilience validation.
-
Cultural Resistance: The idea is inherently uncomfortable. Success requires building a culture of psychological safety where learning from failure is celebrated, and blame is avoided. Leadership buy-in is critical.
-
Tooling is Secondary: While powerful tools exist (like Chaos Monkey, Gremlin, Litmus), they are enablers, not the core. The discipline and practice are primary. You can start simple with custom scripts or basic cloud tooling.
The Strategic Benefits: Why It’s Worth the Effort
Integrating chaos testing yields profound advantages that ripple across technology and business:
-
Increased Availability and Reliability: By proactively finding and fixing weaknesses, you directly reduce the frequency and severity of unplanned outages. This builds user trust and protects revenue.
-
Improved Incident Response: Teams become familiar with failure modes, making actual incidents less stressful and faster to resolve. On-call engineers transition from “firefighters” to “system surgeons.”
-
Confident Scaling and Innovation: When you know your system can handle failures, you can deploy new code, migrate infrastructure, or enter new markets with greater confidence. It de-risks innovation.
-
Cost Optimization: Chaos experiments often reveal over-provisioned resources or unnecessary redundancy, allowing for more efficient infrastructure spending without compromising resilience.
-
A Tangible Competitive Advantage: In a digital world, resilience is a feature. A platform that remains stable and functional when others are failing is a powerful differentiator.
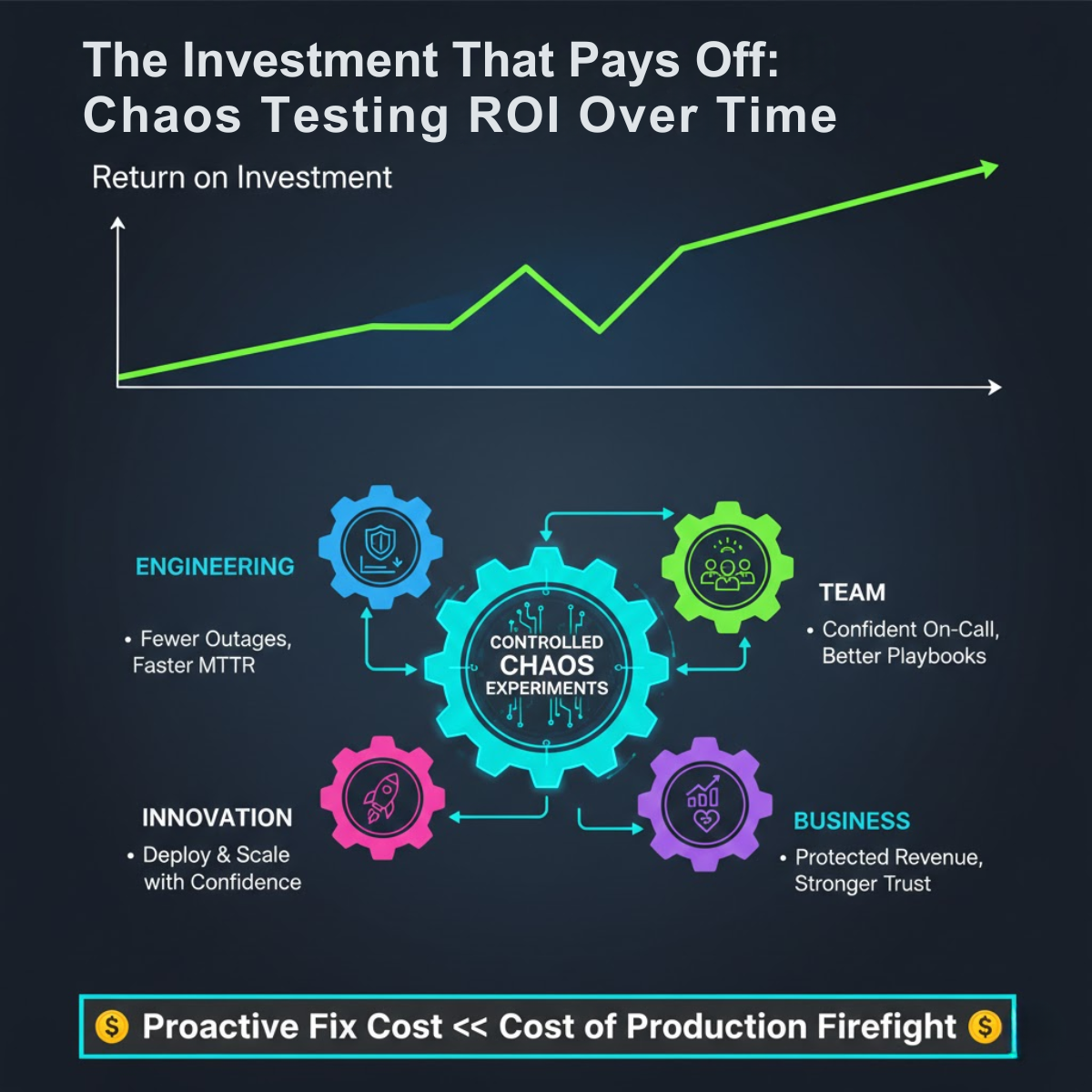
The investment in chaos engineering creates a virtuous cycle, transforming controlled failure into tangible business resilience, customer trust, and a competitive advantage.
Getting Started: A Practical Roadmap
-
Start with Culture and Education: Begin by socializing the principles and success stories. Get buy-in from engineering leadership.
-
Begin in Development: Use chaos principles in a developer’s local environment or a dedicated test cluster. Let engineers experiment with killing their own services safely.
-
Define Your Steady State: Work with product and ops teams to define the key business metrics that represent health.
-
Run Your First “Game Day”: Plan a time-boxed, collaborative event. Manually simulate a failure during off-peak hours (e.g., shut down a secondary database instance) with the full team watching dashboards and practicing response. Document everything.
-
Automate Gradually: As comfort grows, introduce automated, scoped experiments into your production environment, starting with the least critical paths.
-
Integrate and Democratize: Weave chaos experiments into your CI/CD pipeline as a gating mechanism for certain changes. Make the tools and practices accessible to all engineering teams.
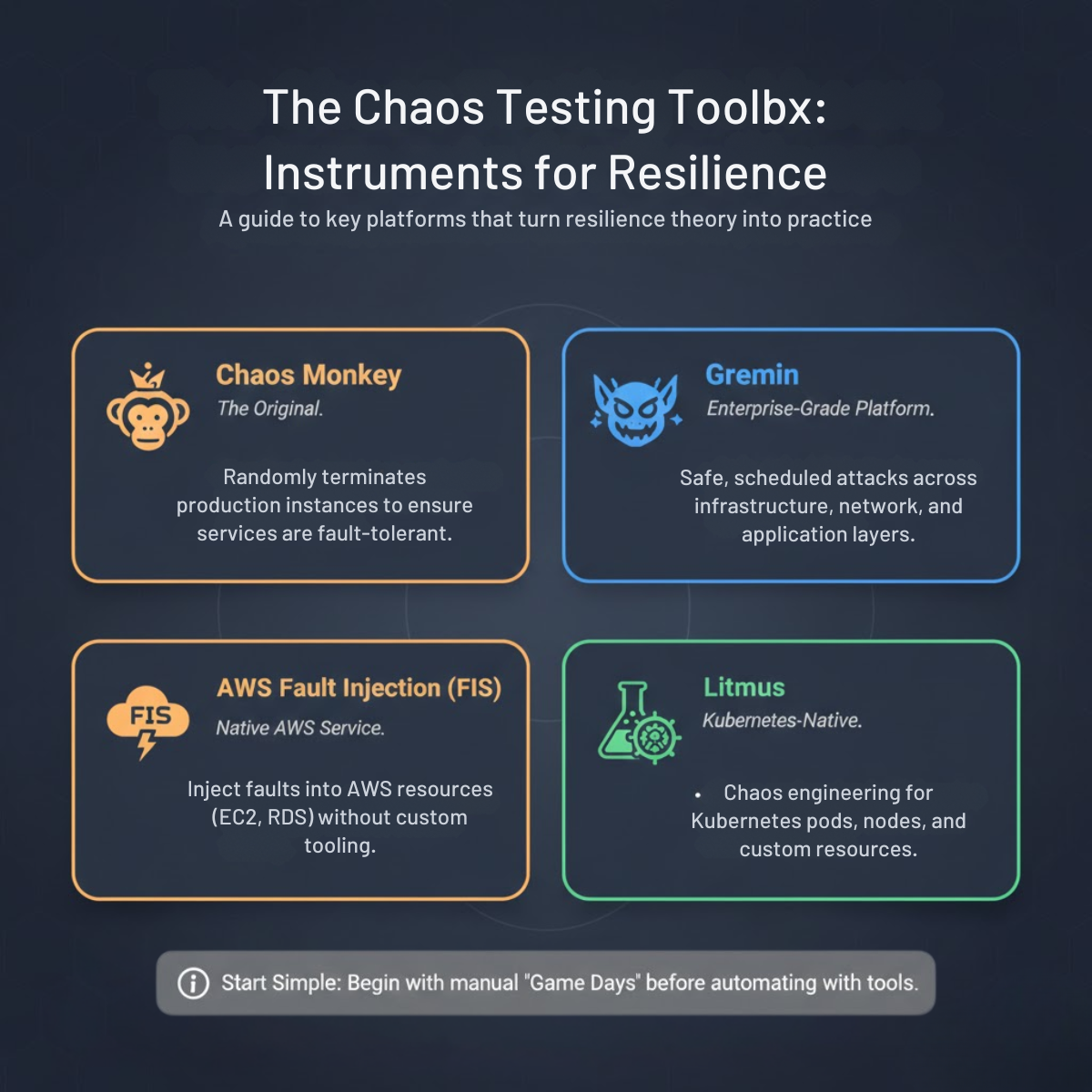
From the pioneering Chaos Monkey to modern Kubernetes-native tools, the right instrumentation turns the theory of chaos engineering into safe, actionable practice.
Conclusion: Embracing the Inevitable
Chaos testing represents a mature evolution in software engineering. It acknowledges the inherent complexity and unpredictability of distributed systems and chooses a path of disciplined, proactive engagement with failure. It moves beyond merely testing software to engineering resilience directly into the fabric of your architecture and team culture.
The journey requires a shift in mindset—from fearing failure to leveraging it as your greatest teacher. The outcome is not just a system that is robust by design, but an engineering team that operates with unparalleled confidence, ready to navigate the inherent chaos of the digital world.
Is your system’s resilience based on hope or evidence? TestUnity’s experts in performance testing and advanced system testing methodologies can guide you in establishing a pragmatic chaos testing practice. We help you build the discipline, select the right tools, and integrate proactive resilience testing into your lifecycle, turning a potential weakness into your strongest asset.
Ready to build unbreakable systems? Explore our performance and reliability testing services or contact a TestUnity expert to discuss building your chaos engineering practice.

TestUnity is a leading software testing company dedicated to delivering exceptional quality assurance services to businesses worldwide. With a focus on innovation and excellence, we specialize in functional, automation, performance, and cybersecurity testing. Our expertise spans across industries, ensuring your applications are secure, reliable, and user-friendly. At TestUnity, we leverage the latest tools and methodologies, including AI-driven testing and accessibility compliance, to help you achieve seamless software delivery. Partner with us to stay ahead in the dynamic world of technology with tailored QA solutions.









The idea of creating resilient systems by introducing failure into the process is definitely a game-changer. So often, we try to make systems perfect for ideal conditions. I think chaos testing opens up a whole new approach to reliability.